After last blog, we built a running cluster with Kubernetes 1.7 and MapR 5.2.1. Now let us try to set up the shared persistent storage in MapR file system for Kubernetes and run some example with Tensorflow and GPU.
Persistent Volume and Persistent Volume Claim
First, we create a MapR volume and point to it with a Persistent Volume and Persistent Volume Claim.
maprcli volume create -name tf_pv1 -path /tf_pv1
mkdir /tf_pv1/data02
mkdir /tf_pv1/checkpoint02
kubectl create -f pv.yaml
pv.yaml:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv001
spec:
capacity:
storage: 80Gi
accessModes:
- ReadWriteMany
nfs:
path: /mapr/DLcluster/tf_pv1/
server: localhost
kubectl create -f pvc.yaml
pvc.yaml:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc001
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 60Gi
We can observe the created volumes in kubernetes dashboard:
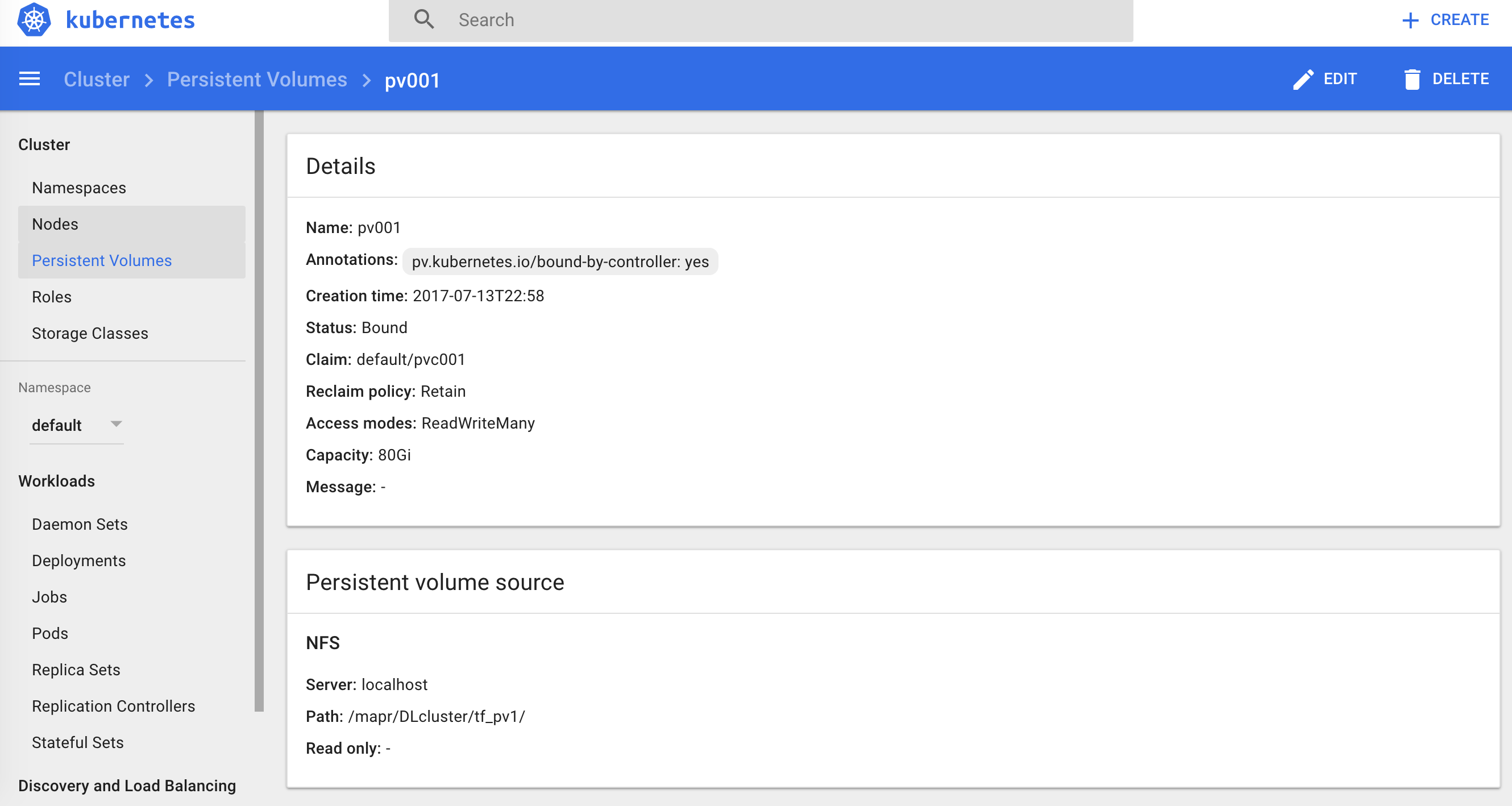
Any content we copy to this mapr volume will be visible to Kubernetes pods attached to persistent volume claim pvc001. As preparation for tensorflow demo, we will download the mnist data and put them in /tf_pv1/data02 from https://pjreddie.com/projects/mnist-in-csv/. Just run a clush ls to make sure your NFS is mounted on the MapR cluster and every node has accesss to MapR file system.

Launch Distributed TensorFlow
Now we will use a YAML file to create 1 parameter server pod and 2 workers pods to demonstrate distributed Tensorflow. Specially, we launch the parameter server on CPU node, and 2 workers on the GPU nodes.
Ideally, there should be a number of ways to launch distributed Tensorflow on Kubernetes. Here, we demonstrate a way that is proven to working and straightforward: we will launch the pod, attach the storage with access to training data, and attach to the pods to run distributed Tensorflow. Note that in the yaml, we attach the pod with persistent volume claim in the last step and we will use that persistent volume claim to host train/test data as well as the python code we actually use to launch distributed tensorflow training task.
apiVersion: v1
kind: ConfigMap
metadata:
name: tensorflow-cluster-config
data:
ps:
"tensorflow-ps-service.default.svc.cluster.local:2222"
worker:
"tensorflow-wk-service0.default.svc.cluster.local:2222,tensorflow-wk-service1.default.svc.cluster.local:2222"
---
apiVersion: v1
kind: ReplicationController
metadata:
name: tensorflow-ps-rc
spec:
replicas: 1
selector:
name: tensorflow-ps
template:
metadata:
labels:
name: tensorflow-ps
role: ps
spec:
containers:
- name: ps
image: gcr.io/tensorflow/tensorflow:latest
ports:
- containerPort: 2222
env:
- name: PS_KEY
valueFrom:
configMapKeyRef:
name: tensorflow-cluster-config
key: ps
- name: WORKER_KEY
valueFrom:
configMapKeyRef:
name: tensorflow-cluster-config
key: worker
securityContext:
privileged: true
volumeMounts:
- mountPath: /tfdata
name: tfstorage001
volumes:
- name: tfstorage001
persistentVolumeClaim:
claimName: pvc001
---
apiVersion: v1
kind: Service
metadata:
labels:
name: tensorflow-ps
role: service
name: tensorflow-ps-service
spec:
ports:
- port: 2222
targetPort: 2222
selector:
name: tensorflow-ps
---
apiVersion: v1
kind: ReplicationController
metadata:
name: tensorflow-worker0-rc
spec:
replicas: 1
selector:
name: tensorflow-worker0
template:
metadata:
labels:
name: tensorflow-worker0
role: worker
spec:
containers:
- name: worker
image: gcr.io/tensorflow/tensorflow:latest-gpu
ports:
- containerPort: 2222
env:
- name: PS_KEY
valueFrom:
configMapKeyRef:
name: tensorflow-cluster-config
key: ps
- name: WORKER_KEY
valueFrom:
configMapKeyRef:
name: tensorflow-cluster-config
key: worker
securityContext:
privileged: true
resources:
requests:
alpha.kubernetes.io/nvidia-gpu: 1
limits:
alpha.kubernetes.io/nvidia-gpu: 1
volumeMounts:
- mountPath: /dev/nvidia0
name: nvidia0
- mountPath: /dev/nvidiactl
name: nvidiactl
- mountPath: /dev/nvidia-uvm
name: nvidia-uvm
- mountPath: /tfdata
name: tfstorage001
- name: libcuda-so
mountPath: /usr/lib/x86_64-linux-gnu
- name: cuda
mountPath: /usr/local/cuda-8.0
volumes:
- name: tfstorage001
persistentVolumeClaim:
claimName: pvc001
- hostPath:
path: /dev/nvidia0
name: nvidia0
- hostPath:
path: /dev/nvidiactl
name: nvidiactl
- hostPath:
path: /dev/nvidia-uvm
name: nvidia-uvm
- name: libcuda-so
hostPath:
path: /usr/lib/x86_64-linux-gnu
- name: cuda
hostPath:
path: /usr/local/cuda-8.0
---
apiVersion: v1
kind: Service
metadata:
labels:
name: tensorflow-worker0
role: service
name: tensorflow-wk-service0
spec:
ports:
- port: 2222
targetPort: 2222
selector:
name: tensorflow-worker0
---
apiVersion: v1
kind: ReplicationController
metadata:
name: tensorflow-worker1-rc
spec:
replicas: 1
selector:
name: tensorflow-worker1
template:
metadata:
labels:
name: tensorflow-worker1
role: worker
spec:
containers:
- name: worker
image: gcr.io/tensorflow/tensorflow:latest-gpu
ports:
- containerPort: 2222
env:
- name: PS_KEY
valueFrom:
configMapKeyRef:
name: tensorflow-cluster-config
key: ps
- name: WORKER_KEY
valueFrom:
configMapKeyRef:
name: tensorflow-cluster-config
key: worker
securityContext:
privileged: true
resources:
requests:
alpha.kubernetes.io/nvidia-gpu: 1
limits:
alpha.kubernetes.io/nvidia-gpu: 1
volumeMounts:
- mountPath: /dev/nvidia0
name: nvidia0
- mountPath: /dev/nvidiactl
name: nvidiactl
- mountPath: /dev/nvidia-uvm
name: nvidia-uvm
- mountPath: /tfdata
name: tfstorage001
- name: libcuda-so
mountPath: /usr/lib/x86_64-linux-gnu
- name: cuda
mountPath: /usr/local/cuda-8.0
volumes:
- name: tfstorage001
persistentVolumeClaim:
claimName: pvc001
- hostPath:
path: /dev/nvidia0
name: nvidia0
- hostPath:
path: /dev/nvidiactl
name: nvidiactl
- hostPath:
path: /dev/nvidia-uvm
name: nvidia-uvm
- name: libcuda-so
hostPath:
path: /usr/lib/x86_64-linux-gnu
- name: cuda
hostPath:
path: /usr/local/cuda-8.0
---
apiVersion: v1
kind: Service
metadata:
labels:
name: tensorflow-worker1
role: service
name: tensorflow-wk-service1
spec:
ports:
- port: 2222
targetPort: 2222
selector:
name: tensorflow-worker1
Now, if you set things up correctly, you should be able to observe 3 running pods in the cluster:

The crucial part now is to test whether your cluster has been set up correctly. We can simple choose a GPU pod and do a test run of Tensorflow following the official tutorial. https://www.tensorflow.org/tutorials/using_gpu. To execute python from a pod, we simply attach to a running pod and run a python shell from the command line, please remember to set the correct environment to include cuda in the pod before your test.
At this point, we have set up our running GPU cluster with MapR and Kubernetes 1.7.
kubectl exec -ti tensorflow-worker0-rc-72s2s -- /bin/bash
export PATH=/usr/local/cuda-8.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
To run distributed Tensorflow, we will attach to each pod, launch parameter server and workers individually. Please watch youtube video for the demo.
The python code we used is attached in the end of this article, we used between graph replication and asynchronous training in distributed Tensorflow. There are two points worth noting: 1, on parameter server, instead of use server.join(), we chose to use tf.FIFOQueue. This is because server.join() will never end itself, the idea is to use management service which launch the parameter server to end it. But here we launch the parameter server inside the pod, hence we use the FIFOQueue to queue workers and when worker sends out finished signal, we kill the parameter servers. 2, you can actually play with the time to launch different workers, if you launch 2nd worker a lot later than the 1st one, you will notice the 1st work wont start training until parameter server receive signal from both. And the worker launched later will start with a much smaller cost, since it has picked the parameter from parameter server.
'''
Distributed Tensorflow example of using data parallelism and share model parameters.
Trains a simple sigmoid neural network on mnist for 20 epochs on three kubernetes pods with one parameter server.
'''
from __future__ import print_function
import tensorflow as tf
import sys,os
import time
import numpy as np
import collections
# input flags
tf.app.flags.DEFINE_string("job_name", "", "Either 'ps' or 'worker'")
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")
tf.app.flags.DEFINE_string("ps_hosts", "",
"Comma-separated list of hostname:port pairs")
tf.app.flags.DEFINE_string("worker_hosts", "",
"Comma-separated list of hostname:port pairs")
tf.app.flags.DEFINE_string("data_dir", "/tmp", "Training directory.")
tf.app.flags.DEFINE_string("train_dir", "/tmp", "log directory.")
FLAGS = tf.app.flags.FLAGS
# config
batch_size = 100
learning_rate = 0.05
training_epochs = 10
logs_path = FLAGS.train_dir
IMAGE_PIXELS = 28
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts.split(",")
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
def dense_to_one_hot(labels_dense, num_classes):
"""Convert class labels from scalars to one-hot vectors."""
num_labels = labels_dense.shape[0]
index_offset = np.arange(num_labels) * num_classes
labels_one_hot = np.zeros((num_labels, num_classes))
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1
return labels_one_hot
def create_done_queue(i):
"""Queue used to signal death for i'th ps shard. Intended to have
all workers enqueue an item onto it to signal doneness."""
with tf.device("/job:ps/task:%d" % (i)):
return tf.FIFOQueue(len(worker_hosts), tf.int32, shared_name="done_queue"+str(i))
def create_done_queues():
return [create_done_queue(i) for i in range(len(ps_hosts))]
class DataSet(object):
def __init__(self,
images,
labels,
reshape=True):
"""Construct a DataSet.
one_hot arg is used only if fake_data is true. `dtype` can be either
`uint8` to leave the input as `[0, 255]`, or `float32` to rescale into
`[0, 1]`.
"""
self._num_examples = images.shape[0]
# Convert shape from [num examples, rows, columns, depth]
# to [num examples, rows*columns] (assuming depth == 1)
images = images.astype(np.float32)
images = np.multiply(images, 1.0 / 255.0)
self._images = images
self._labels = labels
self._epochs_completed = 0
self._index_in_epoch = 0
@property
def images(self):
return self._images
@property
def labels(self):
return self._labels
@property
def num_examples(self):
return self._num_examples
@property
def epochs_completed(self):
return self._epochs_completed
def next_batch(self, batch_size, fake_data=False, shuffle=True):
"""Return the next `batch_size` examples from this data set."""
start = self._index_in_epoch
# Shuffle for the first epoch
if self._epochs_completed == 0 and start == 0 and shuffle:
perm0 = np.arange(self._num_examples)
np.random.shuffle(perm0)
self._images = self.images[perm0]
self._labels = self.labels[perm0]
# Go to the next epoch
if start + batch_size > self._num_examples:
# Finished epoch
self._epochs_completed += 1
# Get the rest examples in this epoch
rest_num_examples = self._num_examples - start
images_rest_part = self._images[start:self._num_examples]
labels_rest_part = self._labels[start:self._num_examples]
# Shuffle the data
if shuffle:
perm = np.arange(self._num_examples)
np.random.shuffle(perm)
self._images = self.images[perm]
self._labels = self.labels[perm]
# Start next epoch
start = 0
self._index_in_epoch = batch_size - rest_num_examples
end = self._index_in_epoch
images_new_part = self._images[start:end]
labels_new_part = self._labels[start:end]
return np.concatenate((images_rest_part, images_new_part), axis=0) , \
np.concatenate((labels_rest_part, labels_new_part), axis=0)
else:
self._index_in_epoch += batch_size
end = self._index_in_epoch
return self._images[start:end], self._labels[start:end]
def read_data_sets(train_dir,
reshape=True,
validation_size=2000):
trainfile = os.path.join(train_dir, "mnist_train.csv")
testfile = os.path.join(train_dir, "mnist_test.csv")
train_images = np.array([], dtype=np.uint8)
train_labels = np.array([], dtype=np.uint8)
test_images = np.array([], dtype=np.uint8)
test_labels = np.array([], dtype=np.uint8)
count = 0
with open(trainfile) as f:
for line in f.readlines():
count+= 1
line = line.strip()
line = line.split(",")
line = [int(x) for x in line]
one_rray = np.array(line[1:], dtype=np.uint8)
train_images = np.hstack((train_images, one_rray))
train_labels = np.hstack((train_labels, np.array(line[0], dtype=np.uint8)))
if count % 10000 == 0:
print(str(count))
if count == 20000:
break
train_images = train_images.reshape(20000, 28*28)
train_labels = train_labels.reshape(20000, 1)
train_labels = dense_to_one_hot(train_labels, 10)
count = 0
with open(testfile) as f:
for line in f.readlines():
count += 1
line = line.strip()
line = line.split(",")
line = [int(x) for x in line]
one_rray = np.array(line[1:], dtype=np.uint8)
test_images = np.hstack((test_images, one_rray))
test_labels = np.hstack((test_labels, np.array(line[0], dtype=np.uint8)))
if count % 10000 == 0:
print(str(count))
test_images = test_images.reshape(10000, 28*28)
test_labels = test_labels.reshape(10000, 1)
test_labels = dense_to_one_hot(test_labels, 10)
if not 0 <= validation_size <= len(train_images):
raise ValueError(
'Validation size should be between 0 and {}. Received: {}.'
.format(len(train_images), validation_size))
validation_images = train_images[:validation_size]
validation_labels = train_labels[:validation_size]
train_images = train_images[validation_size:]
train_labels = train_labels[validation_size:]
train = DataSet(train_images, train_labels, reshape=reshape)
validation = DataSet(validation_images, validation_labels, reshape=reshape)
test = DataSet(test_images, test_labels, reshape=reshape)
Datasets = collections.namedtuple('Datasets', ['train', 'validation', 'test'])
return Datasets(train=train, validation=validation, test=test)
def main(_):
# start a server for a specific task
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
if FLAGS.job_name == "ps":
sess = tf.Session(server.target)
queue = create_done_queue(FLAGS.task_index)
# wait until all workers are done
for i in range(len(worker_hosts)):
sess.run(queue.dequeue())
print("ps %d received done %d" % (FLAGS.task_index, i))
print("ps %d: quitting"%(FLAGS.task_index))
elif FLAGS.job_name == "worker":
# Between-graph replication
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
mnist = read_data_sets(FLAGS.data_dir)
# count the number of updates
global_step = tf.Variable(0)
# input images
with tf.name_scope('input'):
# None -> batch size can be any size, 784 -> flattened mnist image
x = tf.placeholder(tf.float32, shape=[None, 784], name="x-input")
# target 10 output classes
y_ = tf.placeholder(tf.float32, shape=[None, 10], name="y-input")
x_image = tf.reshape(x, [-1, 28, 28, 1])
# model parameters will change during training so we use tf.Variable
tf.set_random_seed(1)
with tf.name_scope("weights"):
W_conv1 = weight_variable([5, 5, 1, 32])
W_conv2 = weight_variable([5, 5, 32, 64])
W_fc1 = weight_variable([7 * 7 * 64, 1024])
W_fc2 = weight_variable([1024, 10])
# bias
with tf.name_scope("biases"):
b_conv1 = bias_variable([32])
b_conv2 = bias_variable([64])
b_fc1 = bias_variable([1024])
b_fc2 = bias_variable([10])
# implement model
with tf.name_scope("softmax"):
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
# specify cost function
with tf.name_scope('cross_entropy'):
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
# specify optimizer
with tf.name_scope('train'):
train_op = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
with tf.name_scope('Accuracy'):
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# create a summary for our cost and accuracy
tf.summary.scalar("cost", cross_entropy)
tf.summary.scalar("accuracy", accuracy)
saver = tf.train.Saver()
summary_op = tf.summary.merge_all()
init_op = tf.global_variables_initializer()
print("Variables initialized ...")
enq_ops = []
for q in create_done_queues():
qop = q.enqueue(1)
enq_ops.append(qop)
sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0),
logdir=logs_path,
summary_op=summary_op,
saver=saver,
global_step=global_step,
init_op=init_op,
save_model_secs=60)
begin_time = time.time()
frequency = 100
# with sv.prepare_or_wait_for_session(server.target) as sess:
with sv.managed_session(server.target) as sess:
# perform training cycles
start_time = time.time()
for epoch in range(training_epochs):
# number of batches in one epoch
batch_count = int(mnist.train.num_examples / batch_size)
count = 0
for i in range(batch_count):
batch_x, batch_y = mnist.train.next_batch(batch_size)
_, cost, step = sess.run(
[train_op, cross_entropy, global_step],
feed_dict={x: batch_x, y_: batch_y, keep_prob: 0.5})
count += 1
if count % frequency == 0 or i + 1 == batch_count:
elapsed_time = time.time() - start_time
start_time = time.time()
print("Step: %d," % (step + 1),
" Epoch: %2d," % (epoch + 1),
" Batch: %3d of %3d," % (i + 1, batch_count),
" Cost: %.4f," % cost,
" AvgTime: %3.2fms" % float(elapsed_time * 1000 / frequency))
count = 0
print("Test-Accuracy: %2.2f" % sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1}))
print("Total Time: %3.2fs" % float(time.time() - begin_time))
print("Final Cost: %.4f" % cost)
for op in enq_ops:
sess.run(op)
sv.stop()
print("done")
if __name__ == "__main__":
tf.app.run()