In current big data enterprise ecosystems, there are always new choices when it comes to analytics and data science. Apache incubates so many projects that people are always confused how to choose from. Among the pipeline of data science, Ad-hoc query is an important aspect, running different queries will lead to exploratory statistics that help understanding the shape of data. In reality, for many company and practices, Hive is still their working horse. As ancient as Hive is, different groups might hack it in a different way to make it handy to use, still, I heard lots of complaints on the query never be able to finish. Spending time waiting on query execution and adjust query results slowed down the pace of data science discovery.
Personally, I like using spark to run the ad-hoc queries comparing with Hive map-reduce program, mostly due to the ease of doing other things on spark at the same time. I don't have to switch back and forth with different tools. Recently, I also looked into Alluxio which is a distributed in-memory file system. In this article, I will demonstrate examples to use SparkSQL, Parquet and Alluxio to speed up Ad-hoc query analytics. Using Spark to accelerate query, data locality is the key.
Install Alluxio with MapR
At first, we begin with an existing MapR 5.1 system running on 3-node AWS instance(m4.2xlarge). We download Alluxio from Github and compile with Mapr5.1 artifacts.
git clone git://github.com/alluxio/alluxio.git
cd alluxio
git checkout v1.2.0
mvn clean package -Dhadoop.version=2.7.0-mapr-1602 -Pspark -DskipTests
Oracle Java 8 is used to compile Alluxio, it is also the same Java MapR system is running on. However, to launch Alluxio webUI, it is required to switch back to Java 7 temporally. We also make a few change to configuration, adding alluxio-env.sh:
ALLUXIO_MASTER_HOSTNAME=${ALLUXIO_MASTER_HOSTNAME:-"node1 host name"}
ALLUXIO_WORKER_MEMORY_SIZE=${ALLUXIO_WORKER_MEMORY_SIZE:-"5120MB"}
ALLUXIO_RAM_FOLDER=${ALLUXIO_RAM_FOLDER:-"/mnt/ramdisk"}
ALLUXIO_UNDERFS_ADDRESS=${ALLUXIO_UNDERFS_ADDRESS:-"/mapr/clustername/tmp/underFSStorage"}
ALLUXIO_JAVA_OPTS+=" -Dalluxio.master.journal.folder=/mapr/clustername/tmp/journal"
Those configuration will put under file storage of Alluxio on Mapr File System as will as master journal, also setting 5GB memory for each Alluxio Working. We can even set up a dedicated volume in MapRFS to serve as the under file system for Alluxio. Also add worker file with hostname of 3 node we planned to have Alluxio Working running.
node1
node2
node3
Therefore, on top of our 3-node MapR cluster, we have an Alluxio architecture that master running on node1, and workers running on node1, node2, node3. We just run a few commands to get alluxio running, and you will be able to reach the webUI at node1:19999
clush -ac /opt/mapr/alluxio/conf
cd /opt/mapr/alluxio/
bin/alluxio format
bin/alluxio-start.sh all
Prepare the data
For comparison purpose, we also build a 4-node cloudera cluster(m4.2xlarge) with CDH-5.8.0 and put alluxio on its 3 data node with same architecture. We run a standalone spark shell on both cluster, with spark-master on node1, 3 worker each with 10GB memory on node[1-3]. We will use a click-through-rate prediction data from Kaggle as sample data we work on, the size is 5.9 GB, contains over 40 million rows. To lauch the spark shell, we use
spark-shell --master spark://node1:7077 --executor-memory 2G --packages com.databricks:spark-csv_2.1:0:1.4.0
In spark shell, we load the csv from maprfs and on hdfs in their respected path.
val trainSchema = StructType(Array(
StructField("id", StringType, false),
StructField("click", IntegerType, true),
StructField("hour", IntegerType, true),
StructField("C1", IntegerType, true),
StructField("banner_pos", IntegerType, true),
StructField("site_id", StringType, true),
StructField("site_domain", StringType, true),
StructField("site_category", StringType, true),
StructField("app_id", StringType, true),
StructField("app_domain", StringType, true),
StructField("app_category", StringType, true),
StructField("device_id", StringType, true),
StructField("device_ip", StringType, true),
StructField("device_model", StringType, true),
StructField("device_type", IntegerType, true),
StructField("device_conn_type", IntegerType, true),
StructField("C14", IntegerType, true),
StructField("C15", IntegerType, true),
StructField("C16", IntegerType, true),
StructField("C17", IntegerType, true),
StructField("C18", IntegerType, true),
StructField("C19", IntegerType, true),
StructField("C20", IntegerType, true),
StructField("C21", IntegerType, true)
))
val train = sqlContext.read.format("com.databricks.spark.csv")
.option("header", "true")
.schema(trainSchema)
.load(trainPath)
Then we write the file three times to generate the data we need: 1, write to alluxio with csv format, 2, write to alluxio with parquet format, 3, write to hdfs/maprfs with parquet format. Since the csv format is already there on hdfs/maprfs.
train.write.parquet("maprfs:///tmp/train_parquet")
train.write.parquet("alluxio://node1:19998/train_parquet")
train.write
.format("com.databricks.spark.csv")
.option("header", "true")
.save("alluxio://node:19998/train_crt")
When we take a look the file size, we can see that parquet file is more efficient in size, 5.9GB csv data is compressed to less than 1GB

Run SparkSQL on Hot Data
This is how we plan to read the data and monitor different performance. I will show how parquet can increase query performance and when it is useful to use Alluxio. Before we read any files, we will remove the OS cache to make more accurate measurement.
clush -a "sudo sh -c 'free && sync && echo 3 > /proc/sys/vm/drop_caches && free'"
| Dist\file type | csv files | parquet files |
| Cloudera | sc.textFile/dataframe csv reader | dataframe parquet reader |
| MapR | sc.textFile/dataframe csv reader | dataframe parquet reader |
We can capture the time of execution through sparkUI, but we can also write a small scala snippet to do that:
val start_time=System.nanoTime()
train.count \\or some other operations
val end_time = System.nanoTime()
println("Time elapsed: " + (end_time-start_time)/1000000 + " milliseconds")
First, we read csv data into RDD with textFile() in spark and do a simple count on csv file. Here, one stange thing you might notice is that cached RDD turns out to be slower. I want to emphasize that because RDD is not compressed much when cached into spark, for example, dataframe/dataset are compressed much more effficiently in spark. Hence with our limited memory assigned, we actually can only cache 15% of the data, just a fraction of the whole. So when trying to run query on cached spark RDD, we want to make sure to assign enough executor memory.
| Dist | MapR | Cloudera |
| textFile | 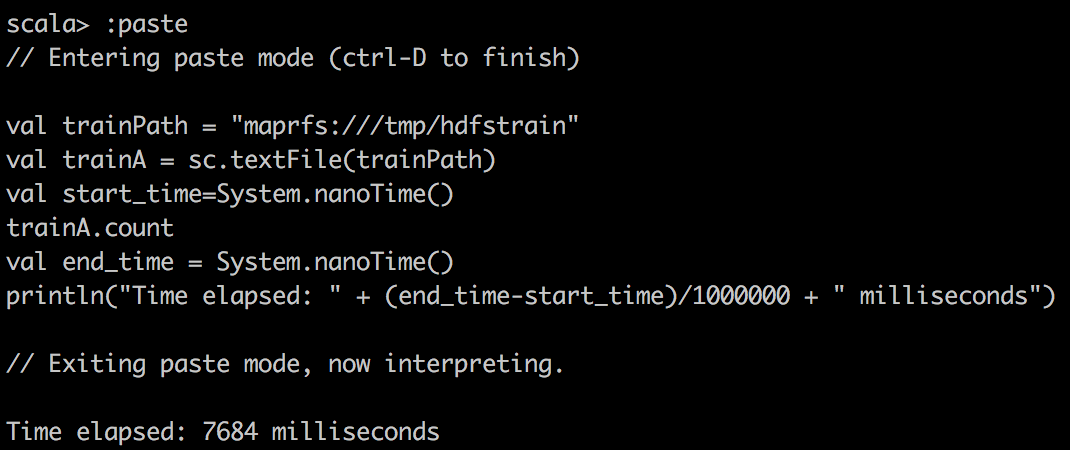 |
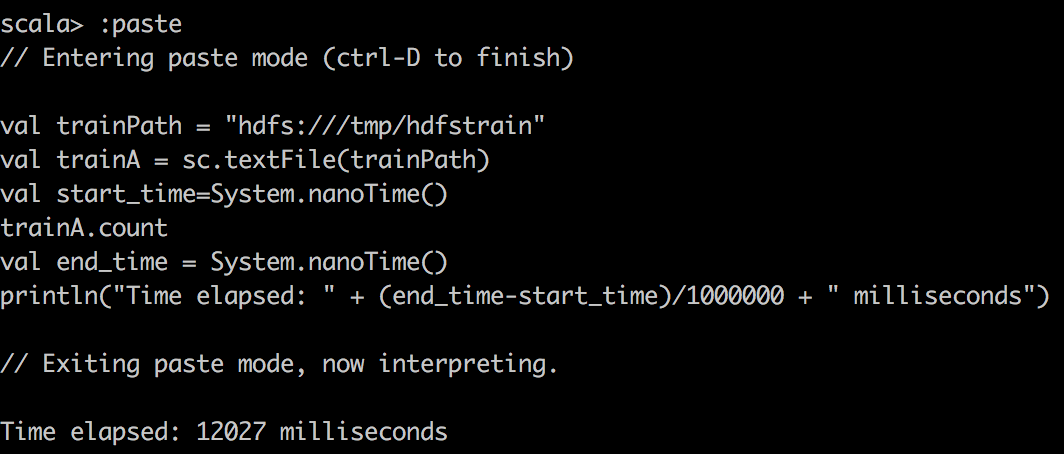 |
| textFile from Alluxio | 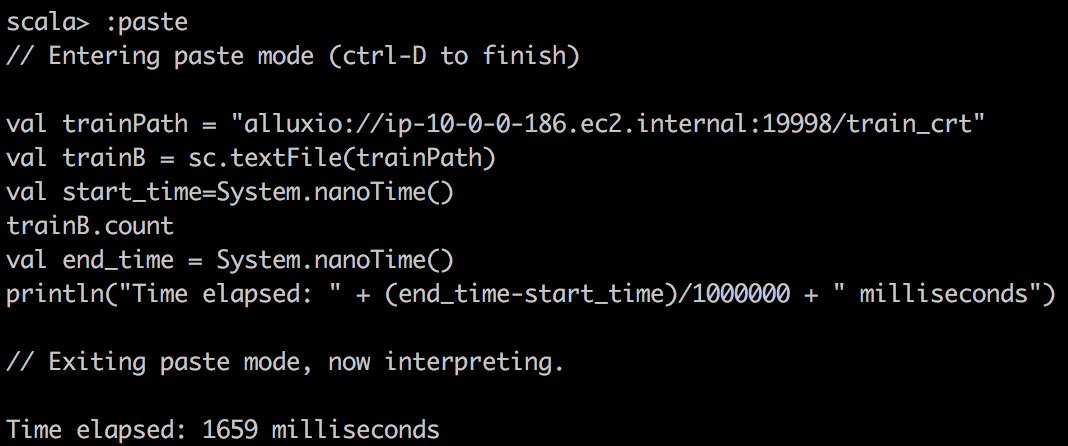 |
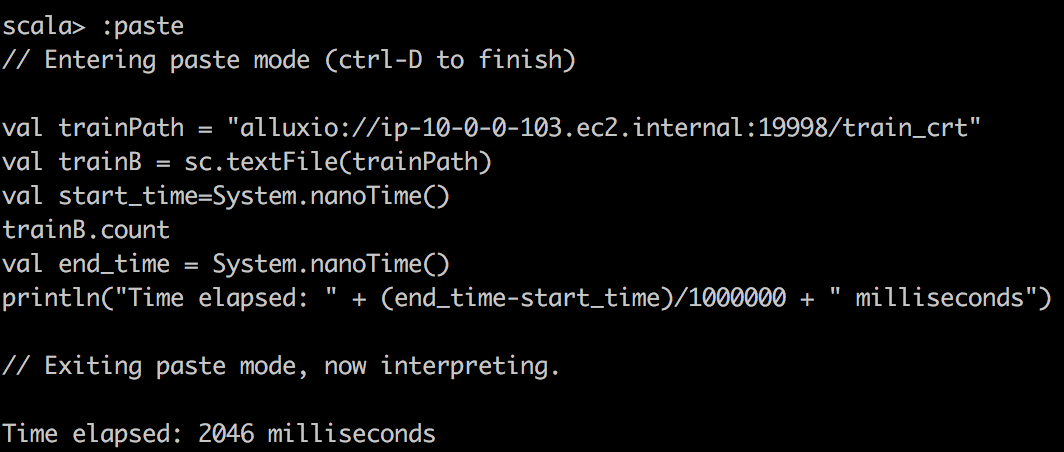 |
| textFile cached | 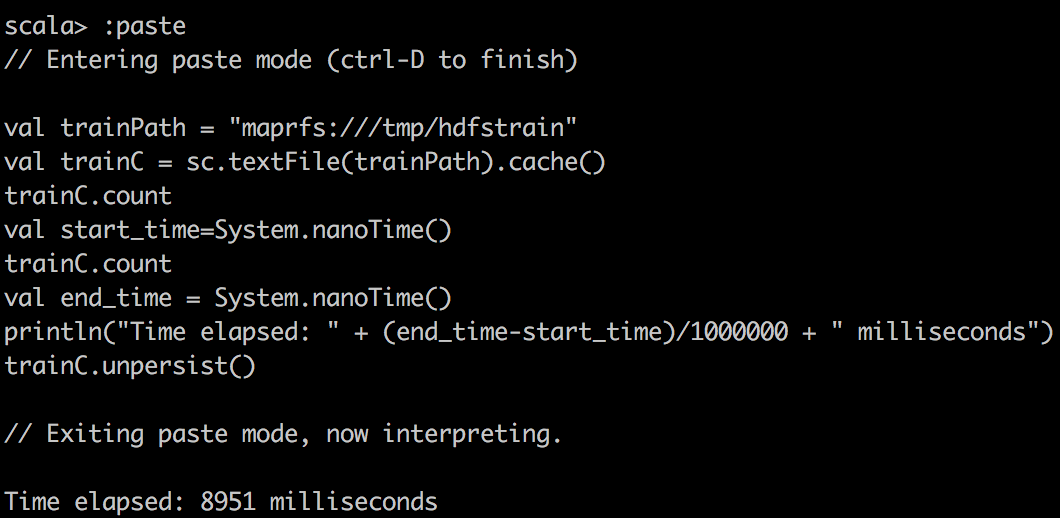 |
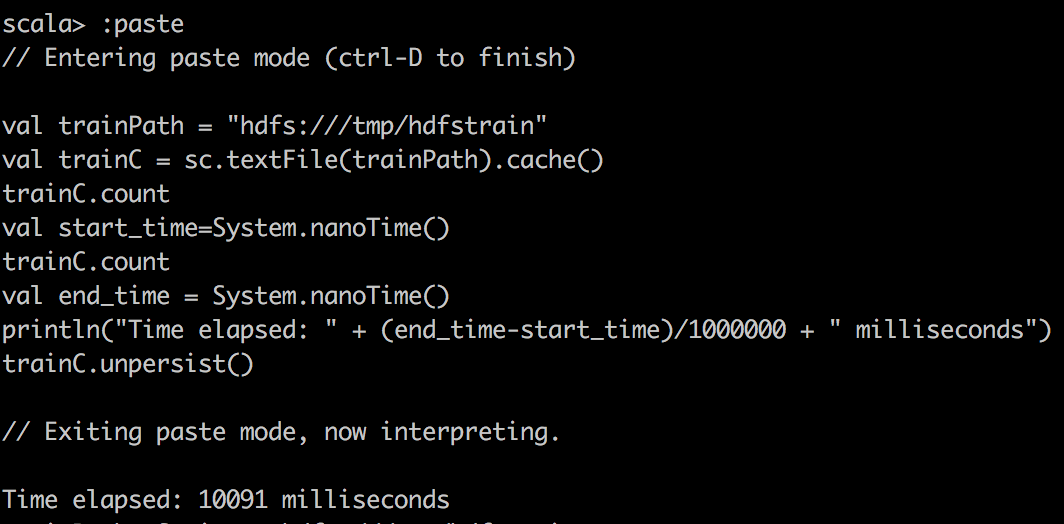 |
| Dist | MapR | Cloudera |
| csv reader | 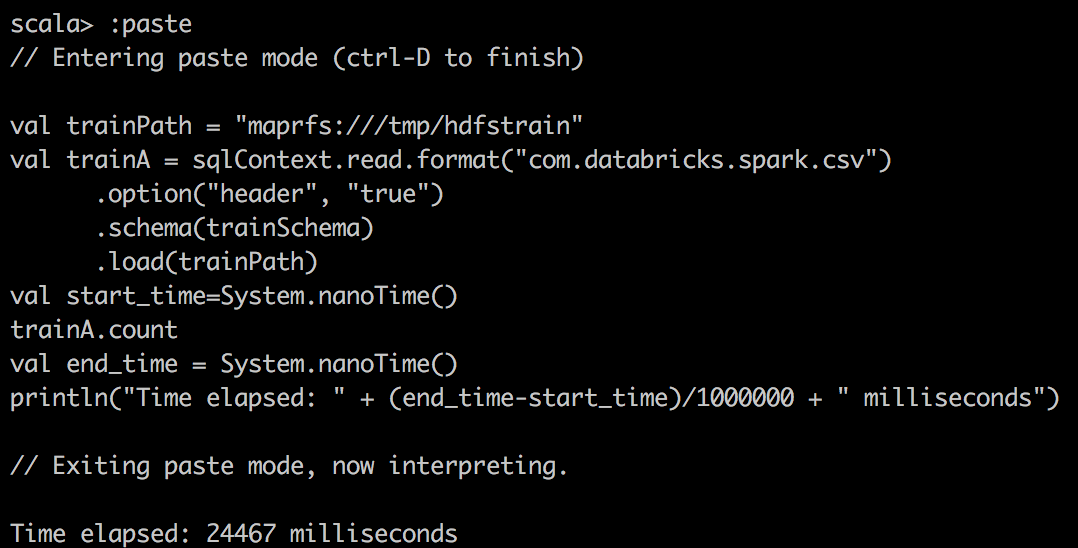 |
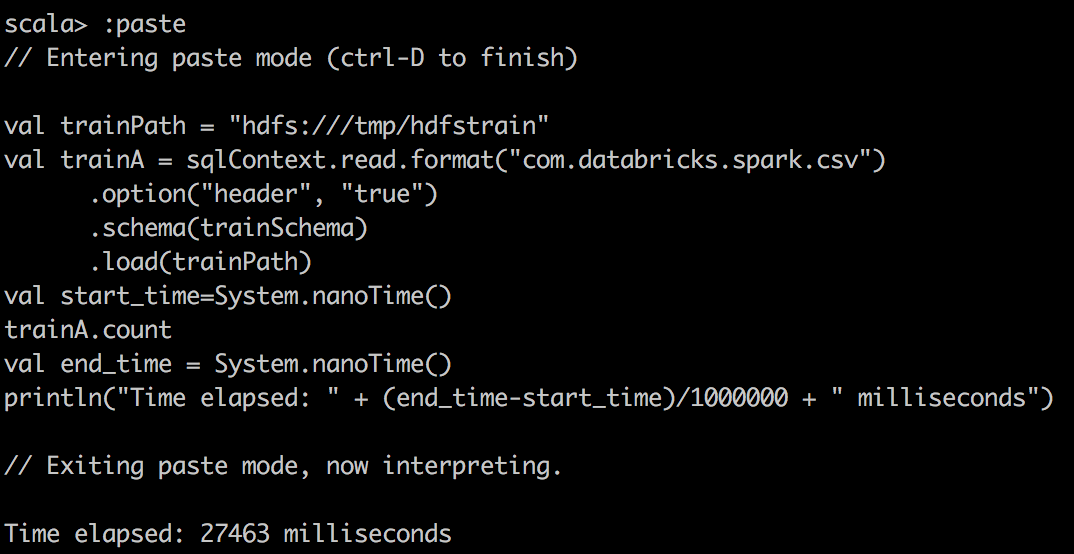 |
| csv reader with alluxio | 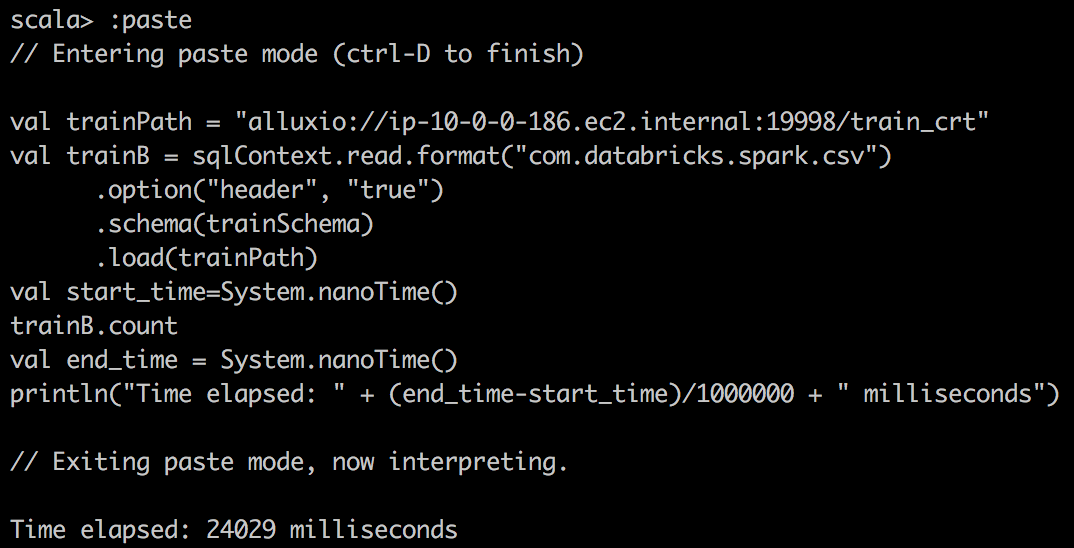 |
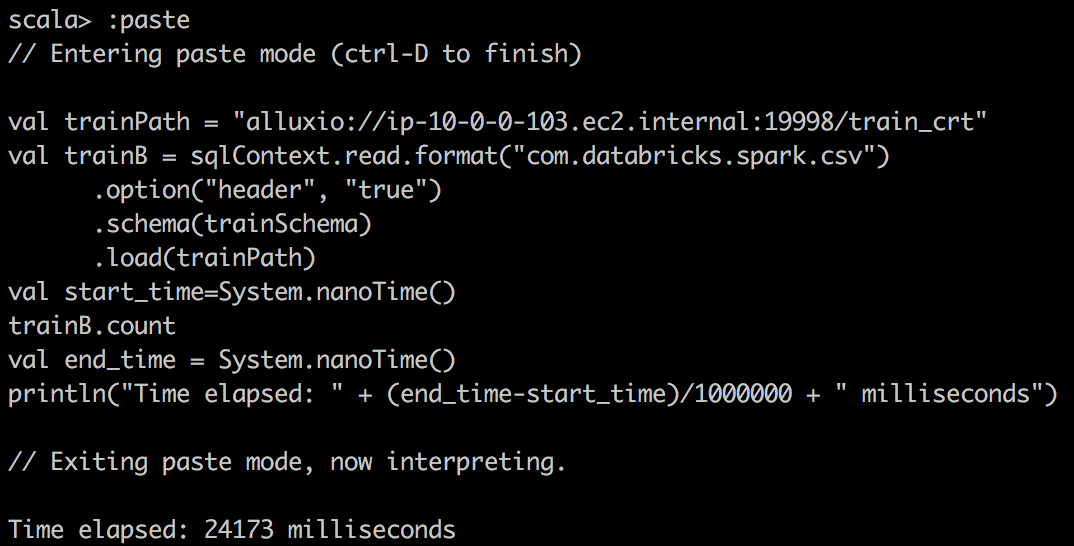 |
| csv reader cached | 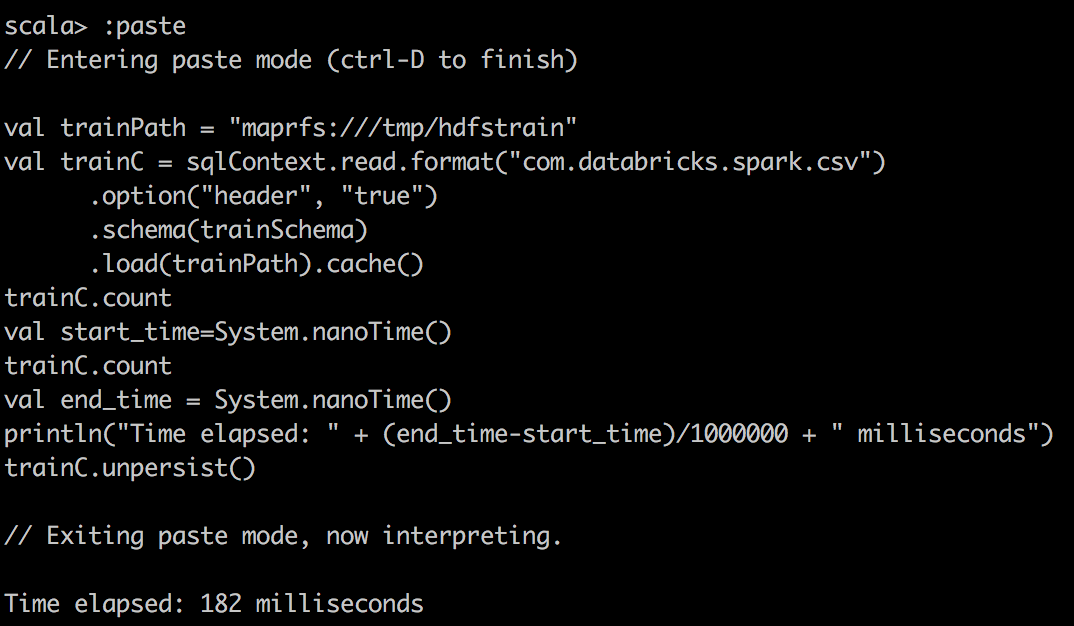 |
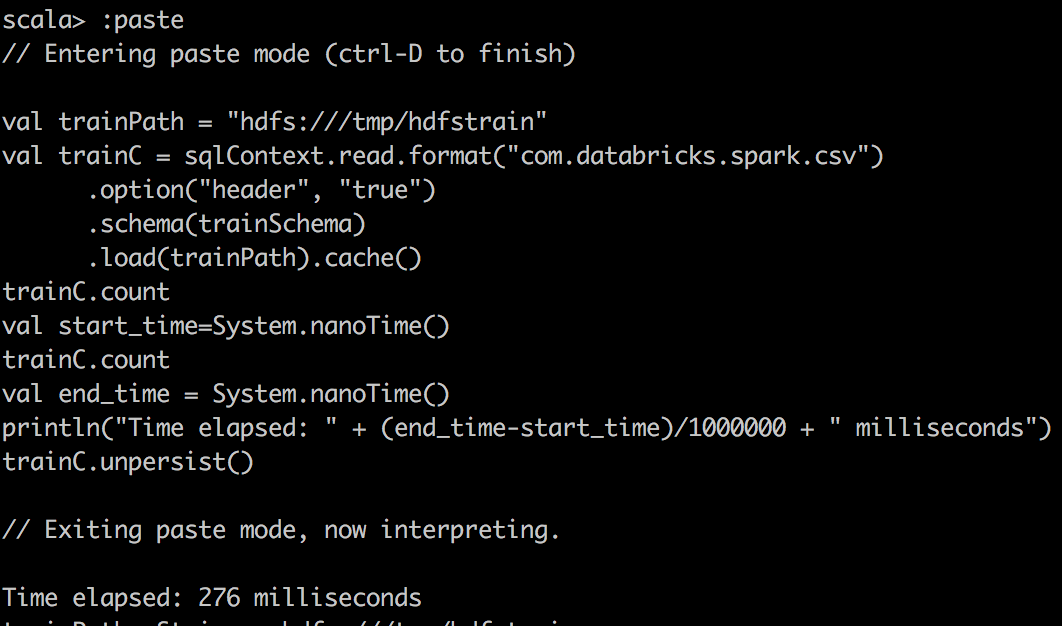 |
| Dist | MapR | Cloudera |
| csv reader | 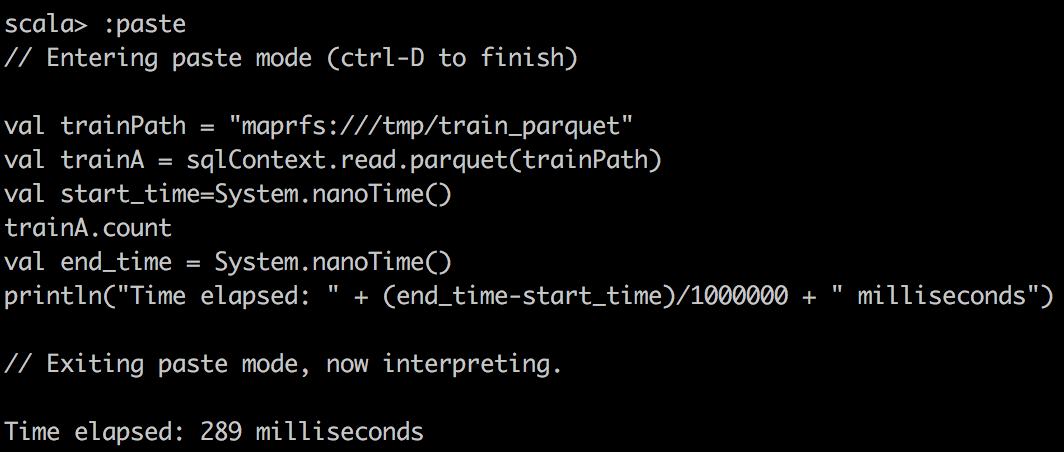 |
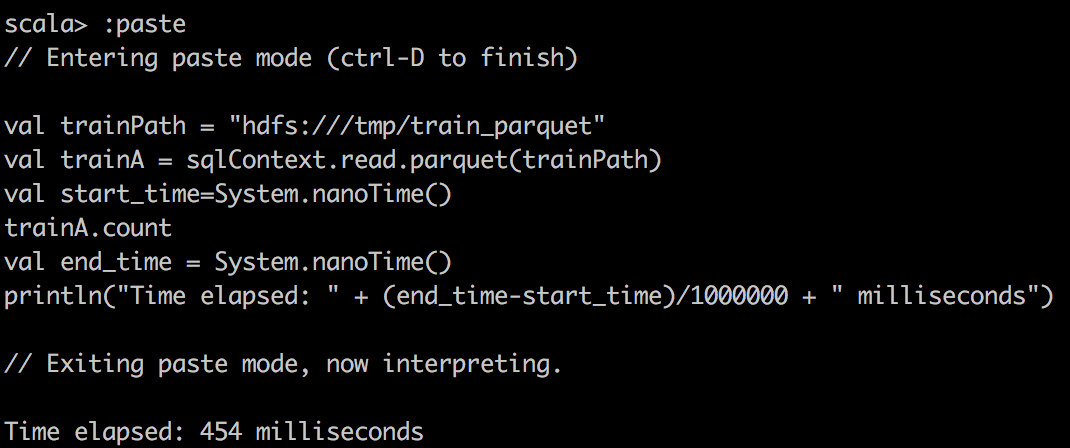 |
| parquet reader with alluxio | 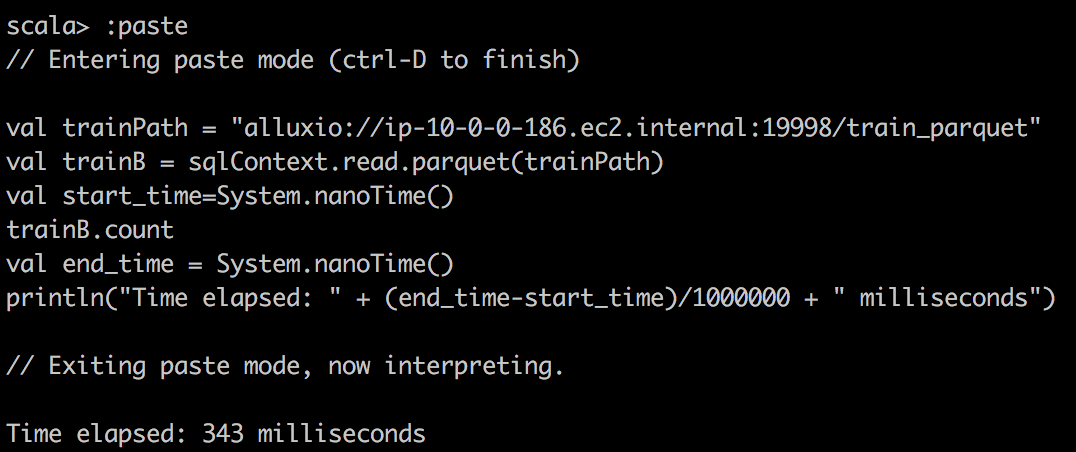 |
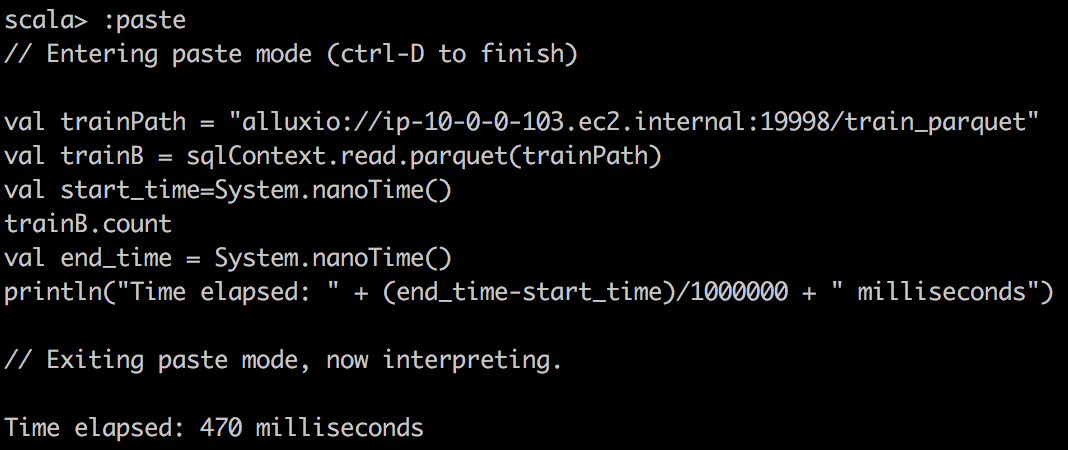 |
| parquet reader cached | 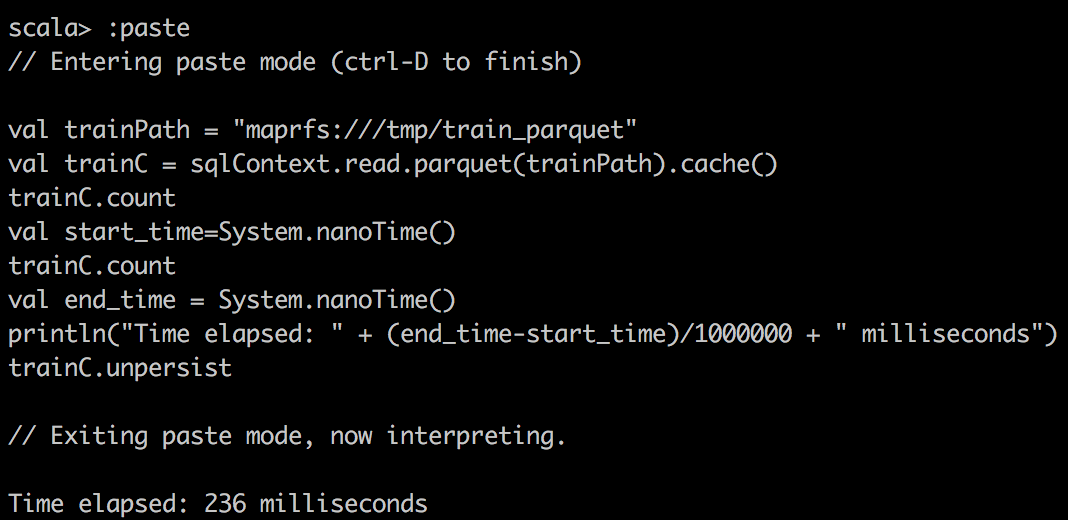 |
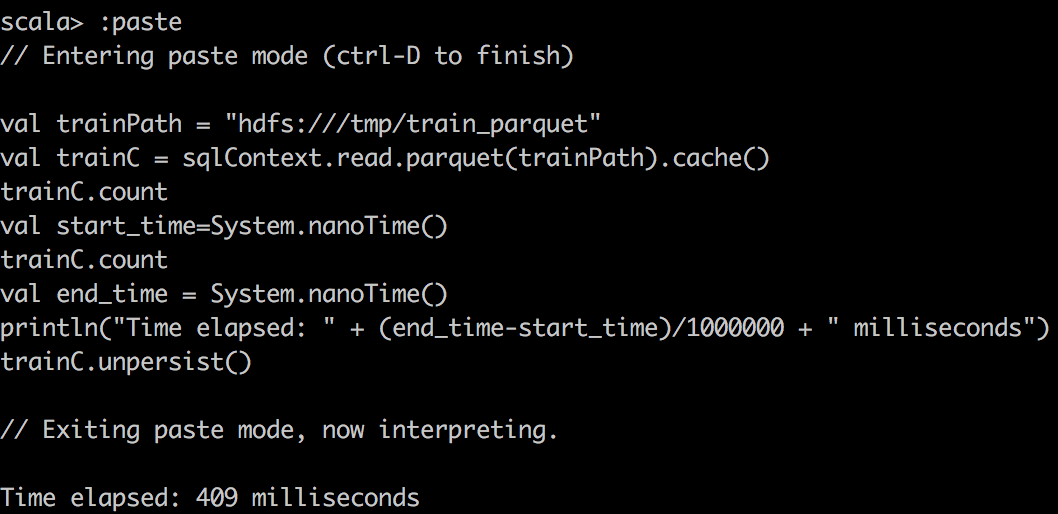 |
| cached | non-cached |
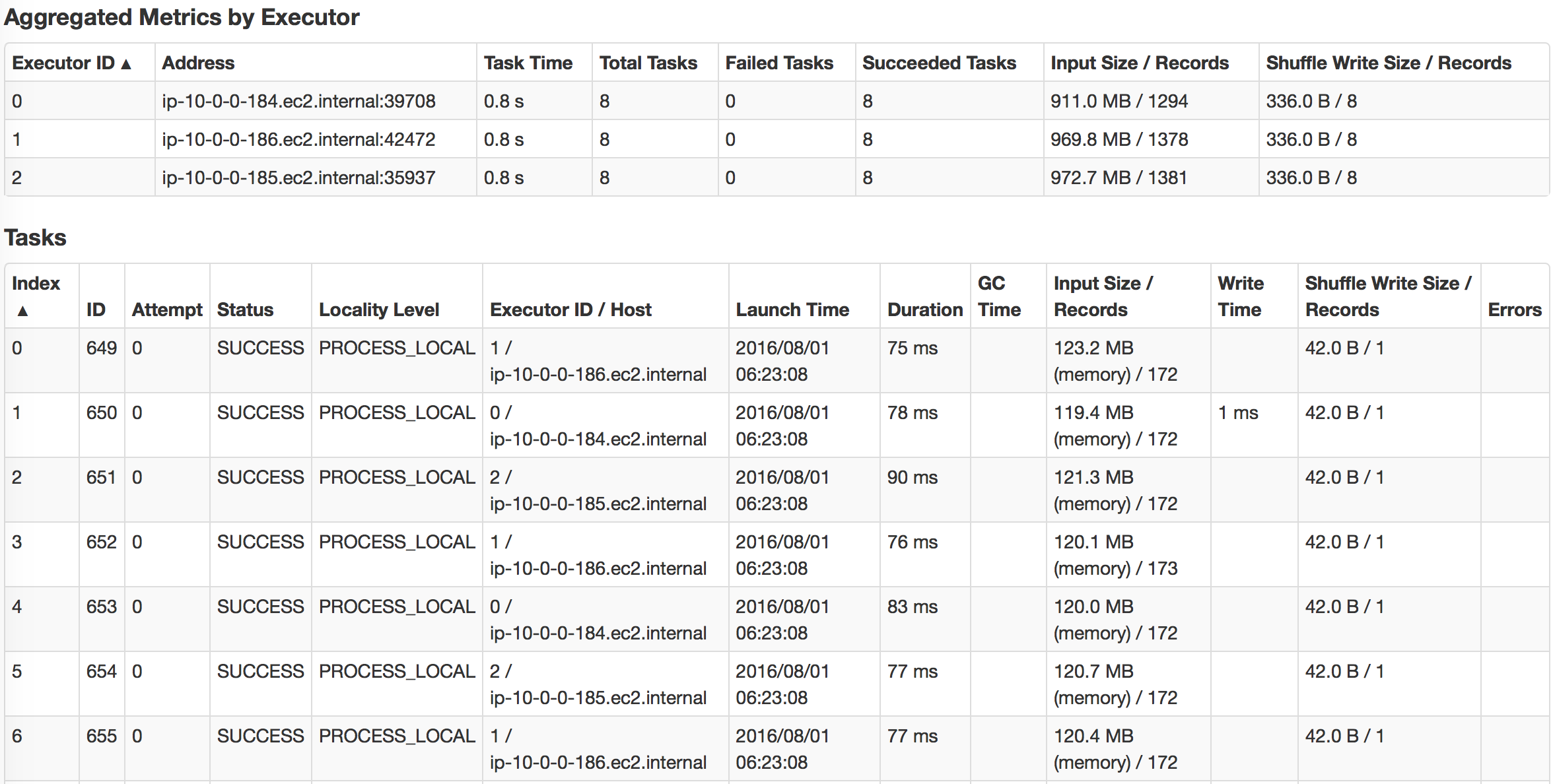 |
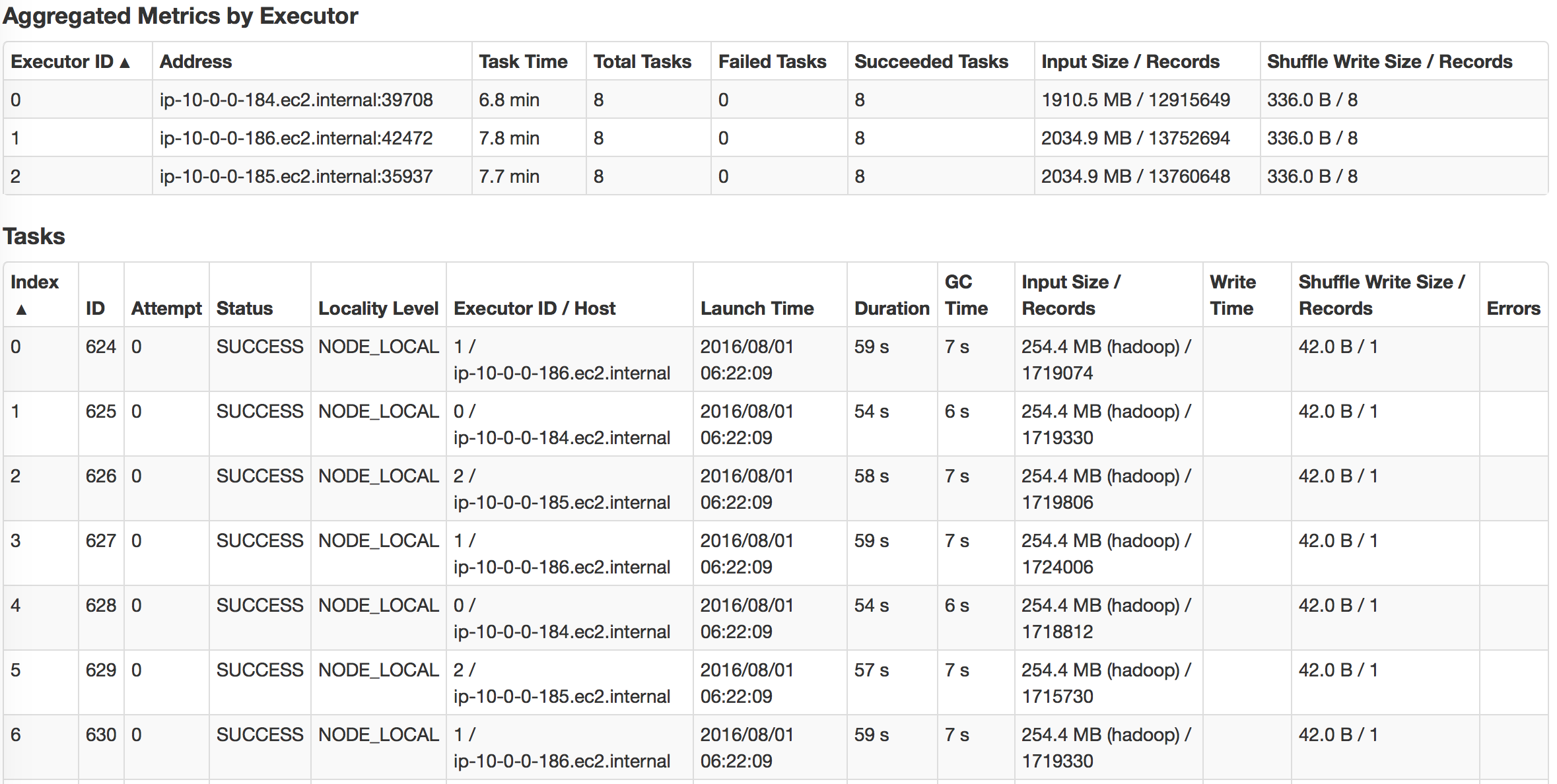 |