Apache PredicitonIO is an open sourced machine learning server. In this article, we integrate Apache PredictionIO with MapR converged data platform 5.1 as backend. Specifically, we use MapRDB (1.1.1) for event data storage, Elastic Search for meta data storage, MapRFS for model data storage.
Introduction
PredictionIO is an open sourced machine learning server, who recently joined the apache family. The strength of PredictionIO includes, quote:
- Quickly build and deploy an engine as a web service on production with customizable templates;
- Respond to dynamic queries in real-time once deployed as a web service;
- Evaluate and tune multiple engine variants systematically;
- Unify data from multiple platforms in batch or in real-time for comprehensive predictive analytics;
- Speed up machine learning modeling with systematic processes and pre-built evaluation measures;
- Support machine learning and data processing libraries such as Spark MLLib and OpenNLP;
- Implement your own machine learning models and seamlessly incorporate them into your engine;
- Simplify data infrastructure management.
PredictionIO is bundled with Hbase, and use it as event data storage manage data infrastructure for machine learning models. In this integration task, we will use MapRDB within MapR converged data platform to replace Hbase. MapRDB implemented directly in the MapR file system. The resulting advantages is that MapRDB has no intermediate layers when performing operations on data. MapRDB runs within MapR MFS process, and reads/writes to disk directly. Whereas Hbase mostly runs on HDFS, which it needs to communicate through JVM and HDFS further need to communicates with linux file system to perform reads/writes. Further advantages could be found here in MapR doc
A few lines of code need to be modified in PredictionIO to work with MapRDB. I have created a forked version that works with MapR 5.1 and Spark 1.6.1. The Github link is https://github.com/mengdong/mapr-predictionio
Preparation
The prerequisite of this article is you have a MapR 5.1 cluster running, with Spark 1.6.1 and Elastic Search 1.7.5 server installed. Java 1.8 is needed and Java 1.7 will experience erros in compiling. Since we use MapRDB (1.1.1) for event data storage, Elastic Search for meta data storage, MapRFS for model data storage. In MapRDB, there is no Hbase namespace concept, so the table hierarchy is based on the hierarchy of MapR file system. MapR support namespace mapping for hbase, details here. Please note that the core-site.xml is located at /opt/mapr/hadoop/hadoop-2.7.0/etc/hadoop/ as of MapR 5.1 and you should modify core-site.xml and add a configuration as below. Also please create a dedicated MapR volume at the path of your choice.
<property>
<name>hbase.table.namespace.mappings</name>
<value>*:/hbase_tables</value>
</property>
Then we download and compile PredictionIO:
git clone https://github.com/mengdong/mapr-predictionio.git
cd mapr-predictionio
git checkout mapr
./make-distribution.sh
After compile, there should be a file PredictionIO-0.10.0-SNAPSHOT.tar.gz created, copy it to a temporary path and extract it there, and copy back the jar file pio-assembly-0.10.0-SNAPSHOT.jar into lib directory under your mapr-predictionio folder.
Since we want to work with MapR 5.1, we want to make sure the proper classpath is included. I have edited bin/pio-class in my repo to include necessary change but your environment could vary, so please edit accordingly. conf/pio-env.sh also needs to be created. I have a template for reference:
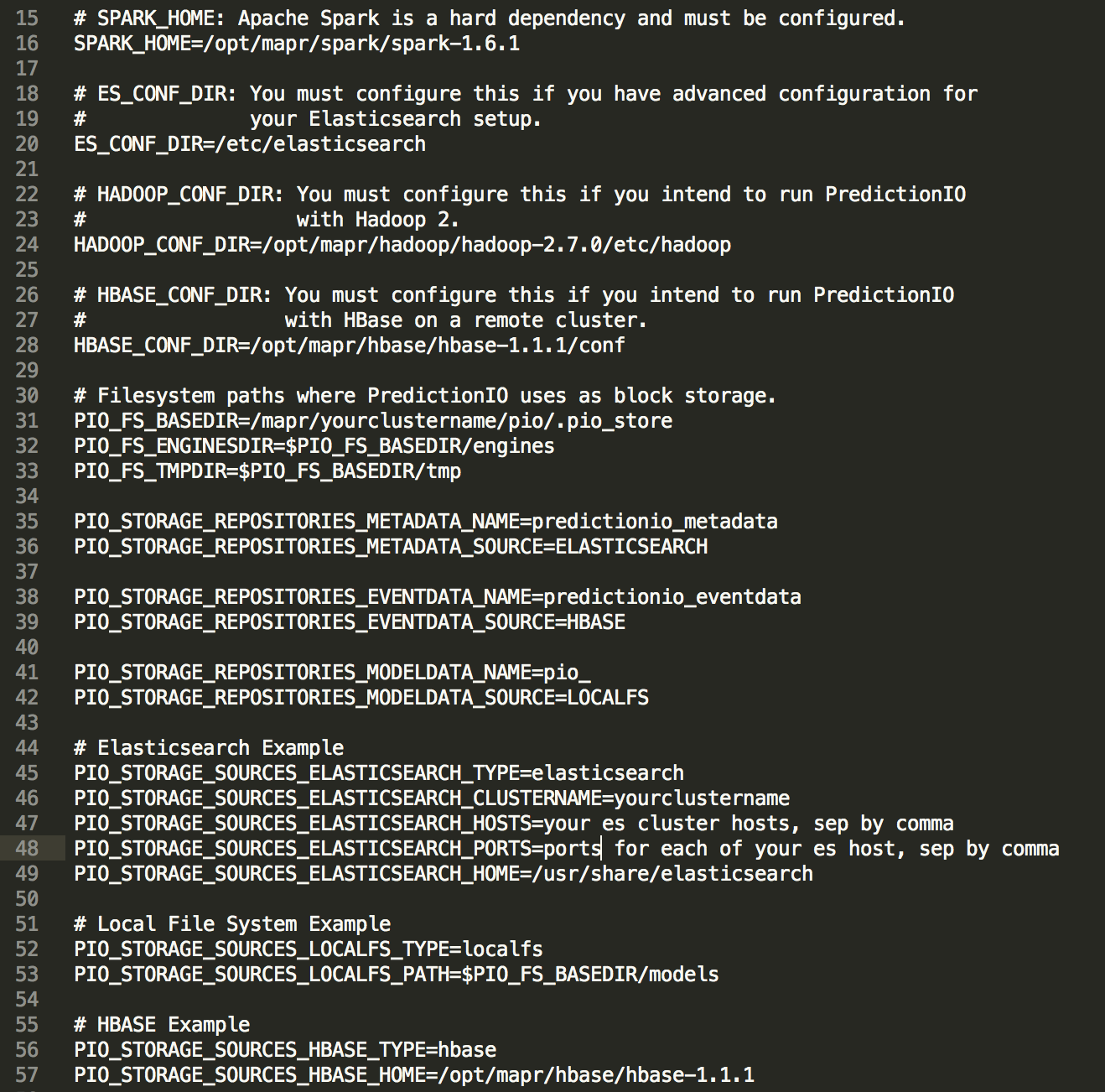
At this point, the preparation is almost finished. We should add bin folder of your PredictionIO to your path. And just run pio status to find out if your setup is successful. If everything works out, you should observe the following log:
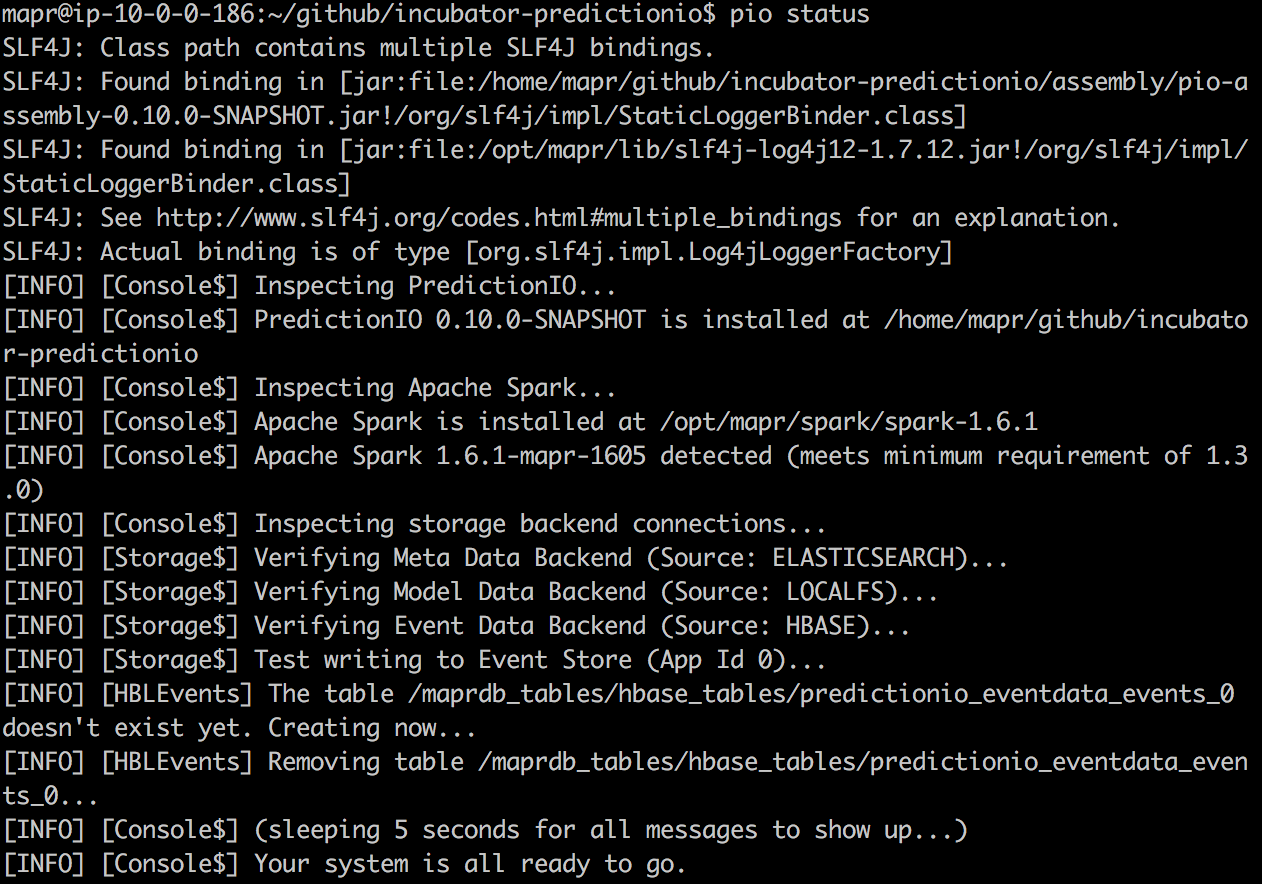
This means it is ready to run bin/pio-start-all to start your PredictionIO console. If it runs successfully, you can just run jps and you should observe a console jvm.
Deploy Machine Learning Models
One excellent feature of PredictionIO is the ease to develop/train/deploy your machine learning application and performs model update and model governance. There are many templates available to demo, for example: spam email detection. Due to the recent migration to apache family, links are broken. I have created forked repo to make a couple templates working. One https://github.com/mengdong/template-scala-parallel-classification is for spam email detection which is a logistic regression trained to do binary spam email classification. Another one https://github.com/mengdong/template-scala-parallel-similarproduct is for similar product, which is a recommendation engine for user and items. You can either clone my forked repo instead of using pio template get. Or, you can copy src folder and build.sbt over to your “pio template get” location. Please modify the package name in your scala code to match your input during template get if you do a copy over.
Everything else works in predictionIO tutorial. I believe the links will be fixed very soon as well. So you can just follow the tutorial to register your engine to a PredictionIO application. Then to train the machine learning model and further deploy the model and use it through REST service or SDK (currently supporting python/java/php/ruby). Further more, you can use Spark and PredictionIO to develop your own model to use MapRDB to serve as the backend.