Introduction
Time series analysis, by definition is to analysis a collection of observations x(t), each one being recorded at time t. The common motivation for time series analysis includes forecasting, clustering, classification, point estimation and detection (in signal process domain).
With the prevalence of sensor technologies, IOT is becoming an inevitable trend. In a highly distributed IOT scenario (automatous driving, oil drilling, healthcare wearable), data with time stamp will be streaming back to data center and stored. Nowadays, the value of data is higher than the value of IOT technology itself. If you can leverage the data as soon as they step into your data center, rather than wait for a certain period and started to do exploratory analysis on those data, you will gain more value from the collected data and be able to take action quickly.
MapR Time Series Quick Start Solution
We aim to solve the time series data collection and forecasting problem at scale here at MapR. The tech stacks we invested are MapR Streams (streaming the event data into your data center), OpenTSDB (high performance time series database to store the data) and Spark (data processing and forecasting).
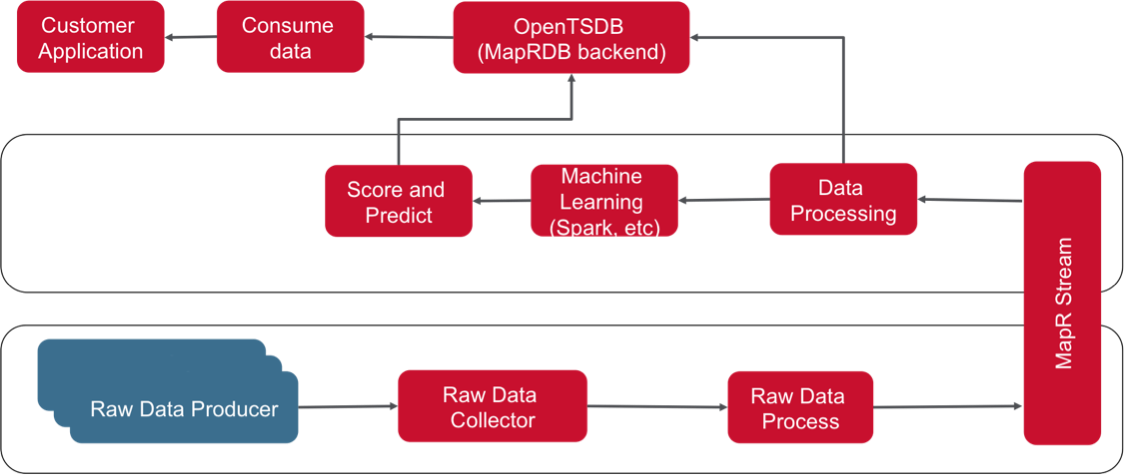
MapR Streams is the integrated publish/subscribe messaging engine in MapR converged data platform. Producer applications can publish messages to topics, which are logical collections of messages, which are managed by MapR Streams. Consumer applications can then read those messages at their own pace. All messages published to MapR Streams are persisted, allowing future consumers to “catch-up” on processing, and analytics applications to process historical data. In addition to reliably delivering messages to applications within a single data center, MapR Streams can continuously replicate data between multiple clusters, delivering messages globally. Like other MapR services, MapR Streams has a distributed, scale-out design, allowing it to scale to billions of messages per second, millions of topics, and millions of producer and consumer applications (details here).
OpenTSDB is an open source scalable time series database with the main backend being HBase. Since MapRDB implements HBase API, we use MapRDB to serve as the backend. The high performance achieved by OpenTSDB is due to a few optimizations specifically targeted at time series data. 1, Use a separate look up table to assign unique IDs to metric names and tag names in the time series data. 2, Reduce the number of rows by storing multiple consecutive data points in the same row so it seeks fast when reading. On MapR, the performance benchmark is that as high as 100 million data point to be ingested per second (more information here).
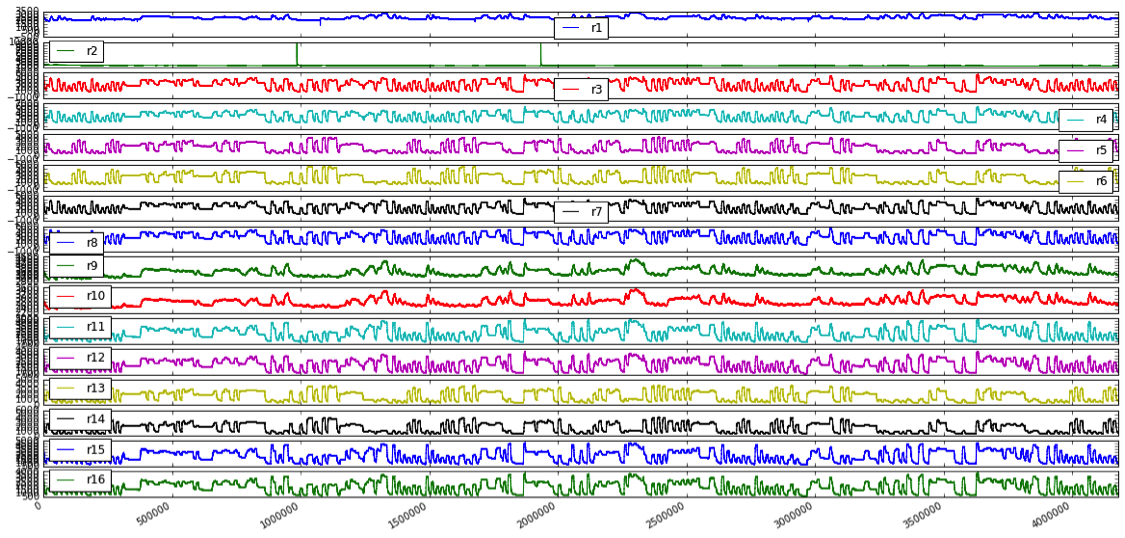
Apache spark provides us with the capacity to harness MapR Streams and provide data processing/parsing function and train machine learning model with multi-variate time series regression algorithms. Our spark streaming code will pick up the data from MapR Streams, briefly process them and write them to OpenTSDB, in the meanwhile, fit the machine learning model to the data and write the prediction into OpenTSDB as well. In our example, we used gas sensor data from UCI machine learning repository (link). With this dataset, we have 16 sensors that monitor the gas content, we try to prediction the ethylene level among the gas based on all sensor readings ahead of time. We use basic linear regression to regress on some auto-regressor features as well as some second derivative features. It is also good practice to look into the seasonality and stationary of the time series data and apply smoothing/differentiation algorithm to prepare the data for processing. For target with obvious on/off status, we also consider combining regression model and binary classification model to further obtain a better RMSE.
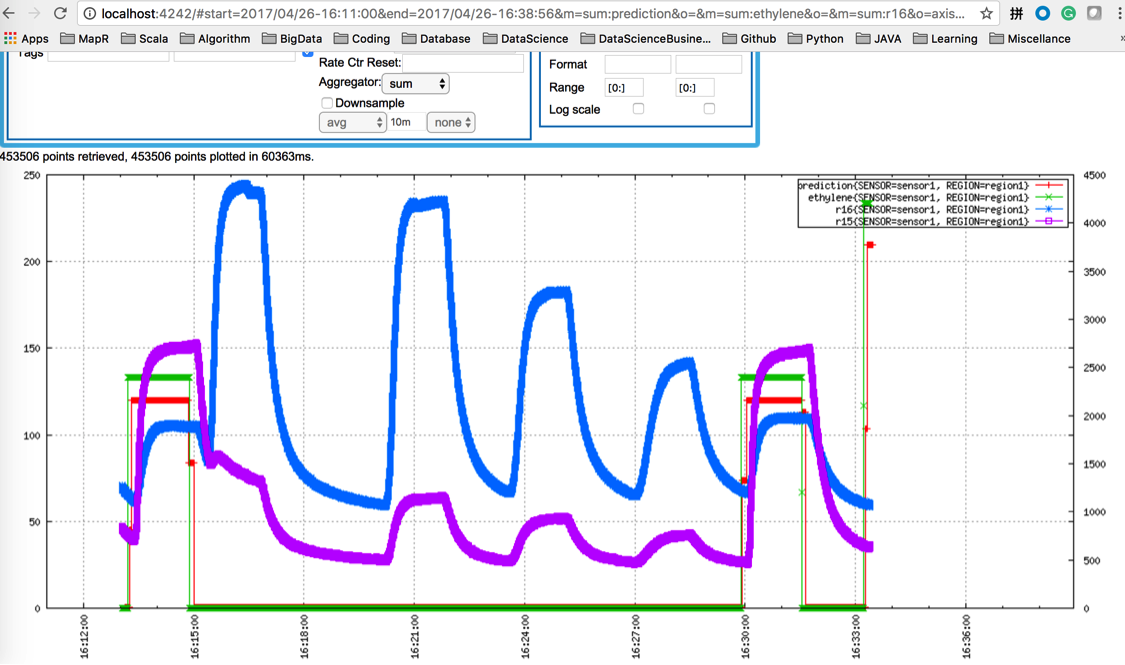
Summary
The focus of this article is more on the solution, while the algorithm applied can be customize given the distribution of the data and requirement of business. I have packaged the quick start solution to extend MapR 5.2 docker container for demo purpose. You can launch the demo on your laptop if you have docker installed, and follow the steps in my docker hub link.
There is a records demo video shows how the docker image works. Note that running docker image is kind of slow due to all the MapR services and OpenTSDB services, also the MapR streaming application and spark application are consuming quite a bit of resource. It will take 15 minutes to start all services and dashboards, another 20 minutes to generate enough data to show meaningful UI on OpenTSDB dashboard